Deep learned closure model for nonlinear Landau damping
We built a differentiable fluid simulation and used it to learn a closure for nonlinear Landau damping — a kinetic effect that depends on the history of wave-particle interactions and cannot be captured by any local fluid model. By introducing a hidden dynamical variable that tracks the resonant electron population and training its growth rate through the simulation itself, we produced the first fluid closure that reproduces trapping-regime physics including wavepacket etching in geometries far outside the training distribution.
[Publication on IOP - Machine Learning: Science and Technology]
A.S. Joglekar and A.G.R. Thomas, Mach. Learn.: Sci. Technol. 4, 035049 (2023)
The idea: learn what fluid equations can’t express
Fluid models of plasma are fast but incomplete. They discard velocity-space information, and when kinetic effects matter — as they do for Landau damping at finite amplitude — that missing information shows up as a closure problem. Linear Landau damping can be handled with a wavenumber-dependent damping term. But at large wave amplitudes, electrons get trapped in the wave potential, suppressing damping through a nonlinear saturation mechanism. No closed-form expression exists for this nonlinear damping rate.
The situation gets worse for finite-length wavepackets. Resonant electrons stream through the wave, eroding it from the rear — an effect called etching. This is intrinsically nonlocal: the damping at one location depends on the upstream history of wave-particle interactions. No closure that depends only on local fluid quantities can capture it.
Our approach: embed a machine-learned dynamical variable directly into the fluid equations and train it by differentiating through the entire simulation.
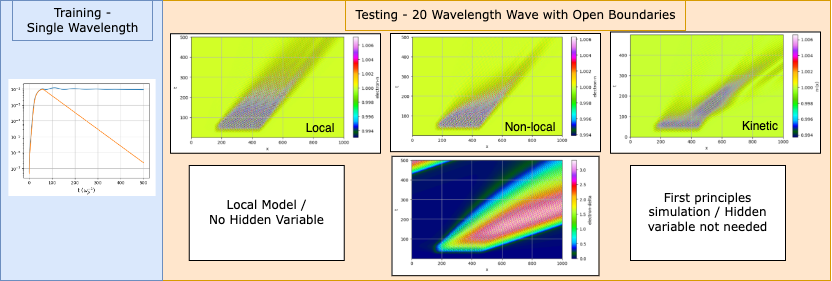
The physics: a hidden variable for resonant electrons
We introduced an auxiliary field, delta(x,t), representing the local population of resonant electrons. This field modifies the Landau damping rate and evolves according to its own transport equation within the differentiable fluid code ADEPT. The coupled system consists of the electron continuity and momentum equations, with damping suppressed by a factor of 1/(1 + delta^2) — a sigmoidal function that shuts off Landau damping when resonant electrons are present.
The hidden variable is advected at the phase velocity (because resonant electrons travel at the phase velocity), grows in response to wave-particle interactions (sourced by |E * nu_L|, the product of electric field and the Landau damping kernel), and saturates at large amplitude (via the same 1/(1 + delta^2) factor). This construction encodes substantial physics. The only unknown is the growth rate coefficient, nu_g, which depends on wavenumber, collision frequency, and wave amplitude but has no known analytical form.
We represented nu_g with a neural network — just 3 layers, 8 nodes wide, 160 total parameters. The network learns a single scalar function; the equations provide all the dynamics.
Key technical choices
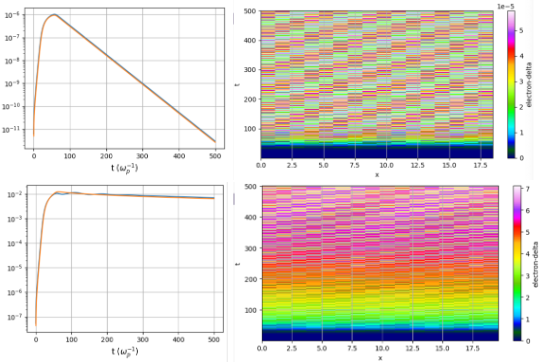
Indirect supervision. The hidden variable delta has no direct counterpart in kinetic theory — it cannot be extracted from a Vlasov simulation. Training therefore requires comparing fluid and kinetic predictions of an observable: the time history of the first density Fourier mode. Gradients are backpropagated through the entire fluid simulation to update the network.
Logarithmic loss. Wave amplitudes can damp over 5-6 orders of magnitude. Without a logarithmic comparison, late-time behavior is invisible to the optimizer. The loss compares log10 of the density mode amplitude between fluid and Vlasov simulations.
Training data. 2535 Vlasov-Poisson-Fokker-Planck simulations spanning collision frequencies from 10^-7 to 10^-3, wavenumbers from 0.26 to 0.40, and initial amplitudes from 10^-6 to 10^-2. Only 200 were used for training (180 train, 20 validation). Each simulation excites a single standing wave in a periodic box of one wavelength.
Main result: from periodic boxes to wavepacket etching
The trained model achieves a test loss of 10^-2 on 2335 held-out simulations. In the linear regime (small amplitudes), the hidden variable stays negligible and standard Landau damping is recovered. In the nonlinear regime (large amplitudes), delta grows and suppresses damping, reproducing the trapping-induced saturation.
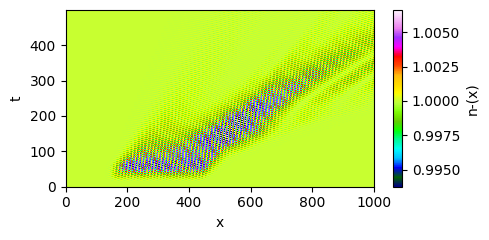
The critical test is generalization. We evaluated the model on domains 100x larger containing finite-length wavepackets with open boundaries — a geometry completely outside the training distribution. Kinetic simulations show wavepacket etching: the rear of the packet erodes faster than the front.
| Vlasov simulation (truth) | Local closure (fails) |
|---|---|
 |
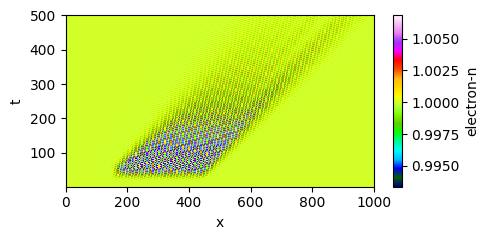 |
A local closure, even one that correctly handles amplitude-dependent damping, produces spatially uniform decay — it has no mechanism for the asymmetry. The hidden-variable model reproduces the etching without any retraining.
| Learned closure (succeeds) | Hidden variable delta(x,t) |
|---|---|
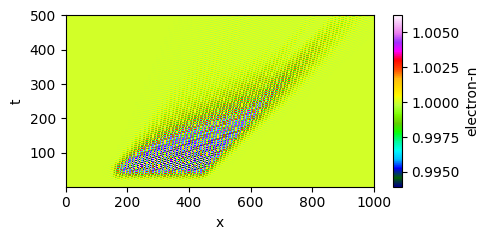 |
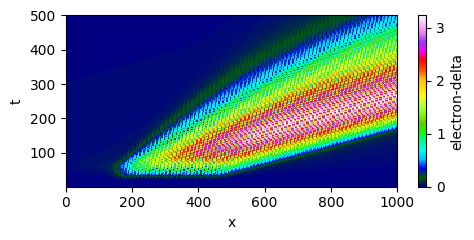 |
Interpretation: spatial memory through transport
The mechanism is visible in the delta field (bottom-right above). The hidden variable grows where wave-particle interactions are strong, then advects forward at the phase velocity, carrying the “memory” of resonant electron production to downstream locations. This spatiotemporal nonlocality — the fact that damping here depends on what happened upstream — emerges naturally from the transport equation structure. The neural network never saw a wavepacket during training, yet the physics encoded in the equations generalizes.
This is the core principle: by embedding the neural network within a PDE system that encodes transport, saturation, and the correct characteristic velocity, the learned model generalizes far beyond its training distribution. The network learns a coefficient; the equations provide the structure.
How it was done
- Solver: ADEPT (Automatic-Differentiation-Enabled Plasma Transport), a differentiable fluid code built in JAX
- Training simulations: 180 single-wavelength Vlasov-Poisson-Fokker-Planck runs (from 2535 total), subsampled across collision frequency, wavenumber, and amplitude
- Neural network: 3 layers, 8 nodes wide, tanh activations, 160 parameters total
- Optimizer: ADAM with data-parallel gradient averaging across 20 compute nodes, ~25 epochs
- Test geometry: 100x larger domains with finite-length wavepackets (~20 wavelengths) and open boundaries
Broader implications
The hidden-variable approach extends naturally to other multiscale problems where kinetic effects must be represented in fluid models — hot electron transport and nonlocal heat flow in inertial fusion plasmas, or kinetic corrections to MHD in the solar wind. The recipe is general: identify a reduced representation that captures the essential nonlocality, embed it in a differentiable solver, and let indirect supervision through the simulation do the rest.
[Publication on IOP - Machine Learning: Science and Technology]